NREL Geospatial Research Scientist Interview
National Renewable Energy Laboratory
October 13, 2022
Environmental Data Science
Obtained a Master of Environmental Data Science degree from UC Santa Barbara June 2022
Besides going to the beach and paddle boarding with my dog, I expanded my technical skills with
- geospatial analysis
- statistics
- remote sensing
- scientific programming with Python and R
- modeling environmental systems
- data visualization
…and fell in love with the concept of reproducible open science

Albedo Importance
- Regulates the Earth’s temperature by reflecting solar radiation
- Influences rate of snow melt
- Particularly important in the Western US
- Accurate estimates critical for climate models and predicting water storage


Snow Today
- Scientific analysis website that provides data on snow conditions from satellite and surface measurements
- Used by scientists, water managers, and outdoor enthusiasts for snow observations
- Spatial products offered include measures of snow cover extent and albedo
Snow Today: Usability

Snow Today can be hard to navigate for new users unfamiliar with the website’s layout
Visualizations are of current snow conditions, and have limited customization options
Snow cover and albedo files are hard to find
Data format may be challenging for new users
Snow metadata is stored in a non-standardized format which is difficult for some software to interpret the data
Users may have trouble processing and analyzing snow data without the help
Snow Today: Visualizations
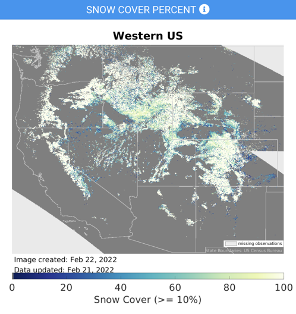
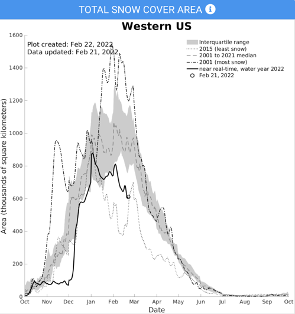
Objectives

Create an open source workflow for processing and visualizing snow data
- Provide recommendations for the Snow Today website
- Create interactive visualizations
- Improve data usability through tutorials in Python
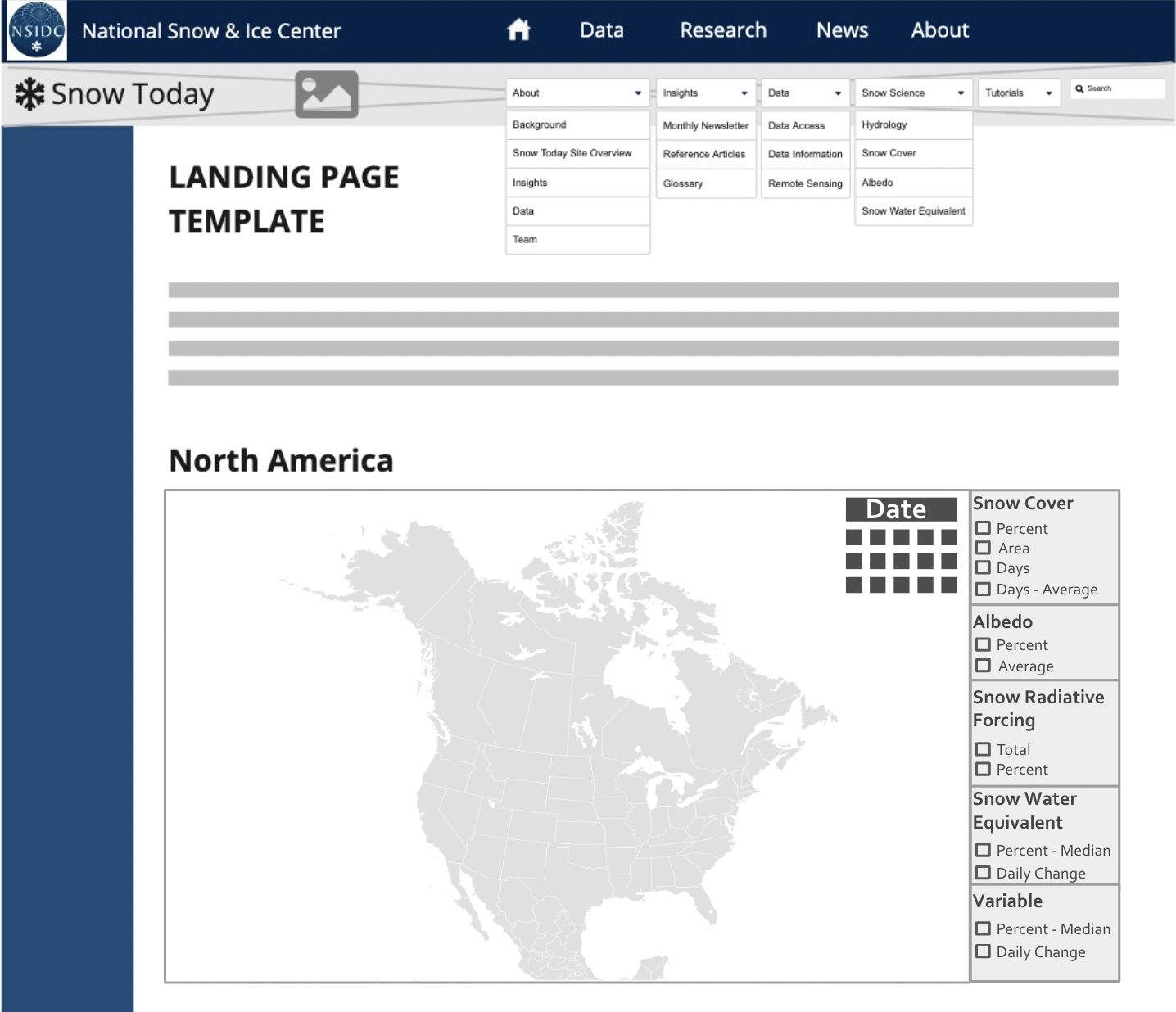
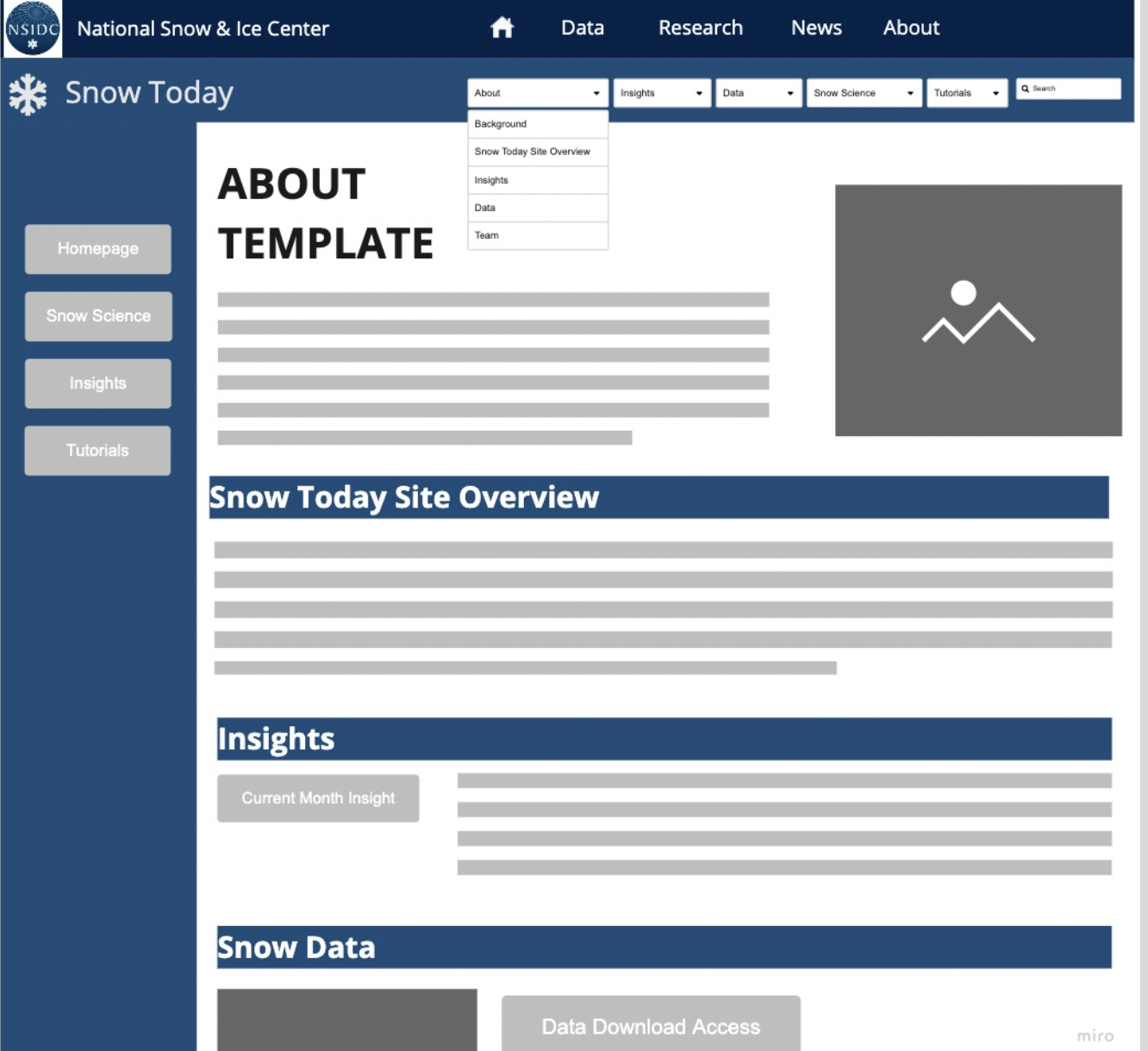
Website Recommendations
website architecture
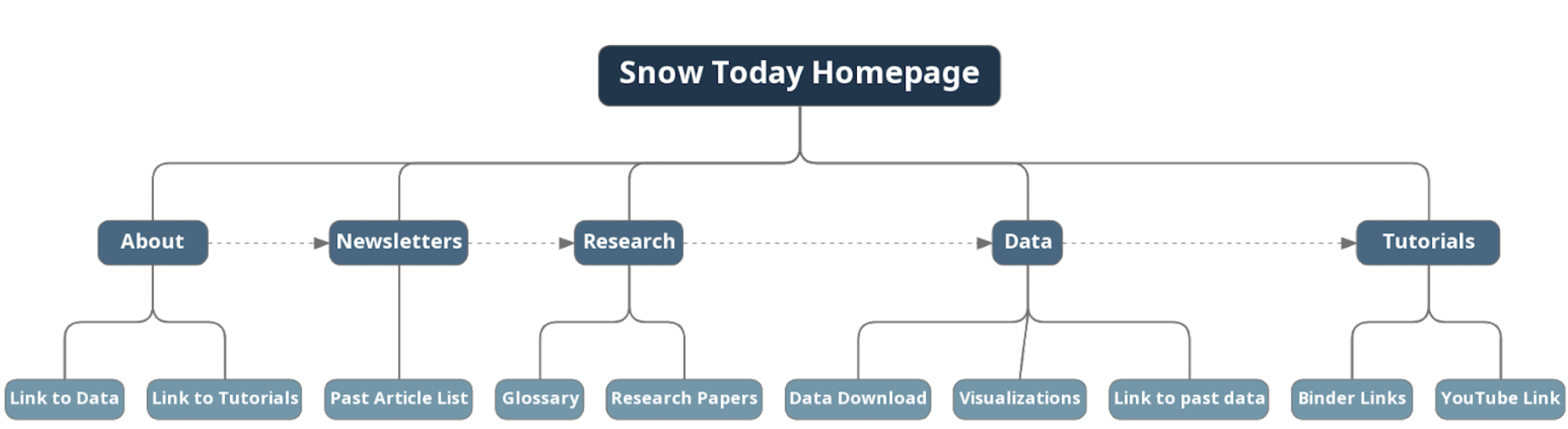
Website Recommendations
Objectives
Create an open source workflow for processing and visualizing snow data
- Provide recommendations for the Snow Today website
2. Create interactive visualizations
- Improve data usability through tutorials in Python
Interactive Visualizations
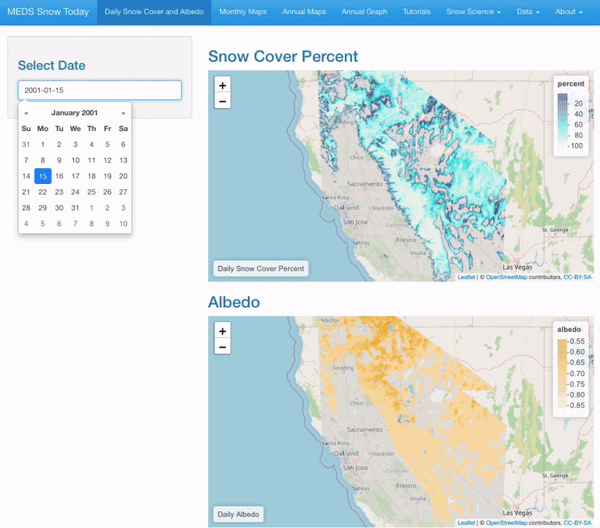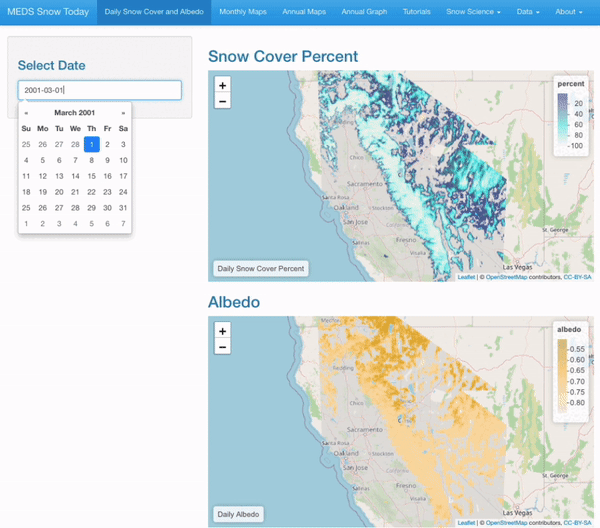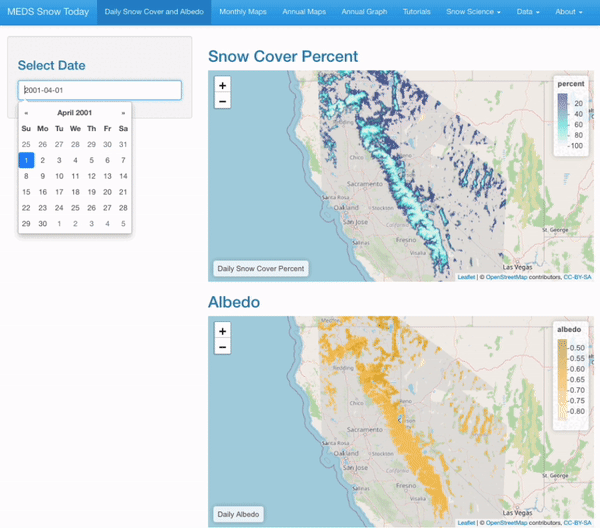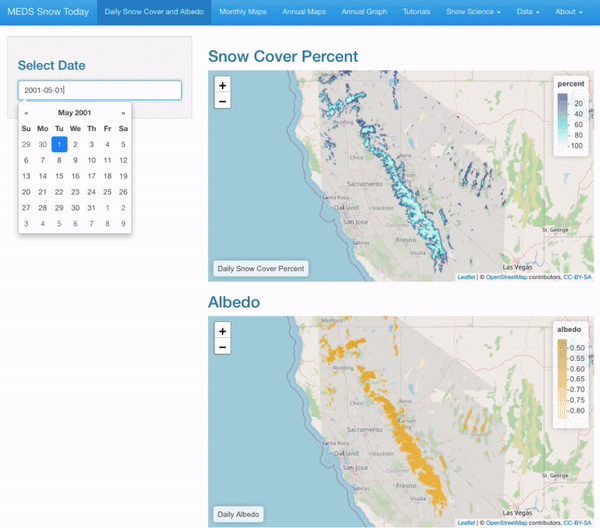
Prototype Web Application
Daily maps of snow cover and albedo for any selected date
Interactive Visualizations
Monthly Average and Anomaly
Users can select a specific month, water year, and variable to view averages on anomalies.
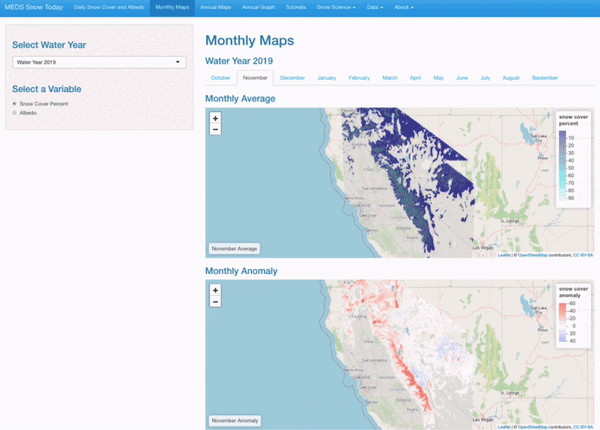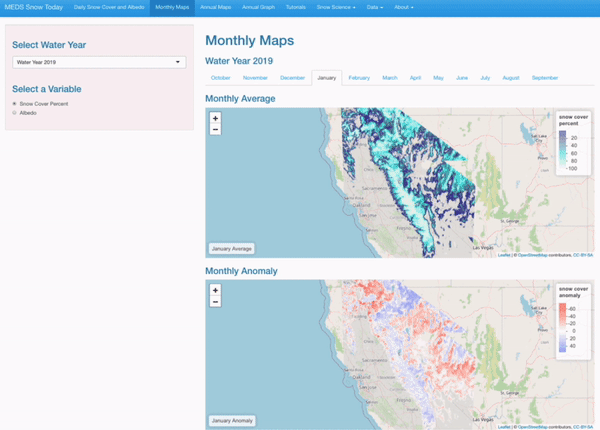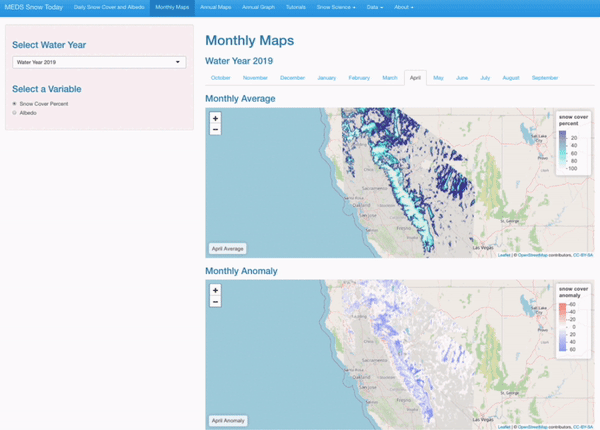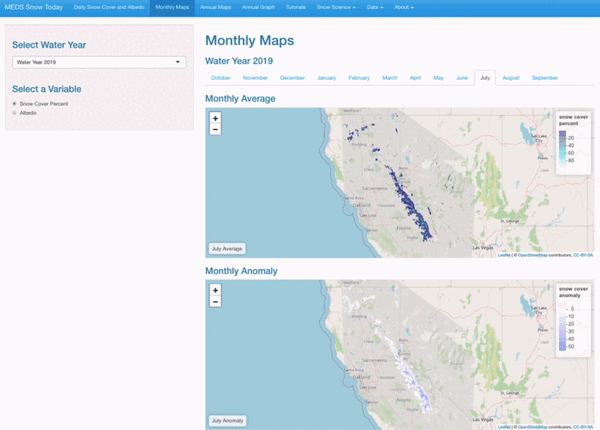
Interactive Visualizations
Annual Comparisons
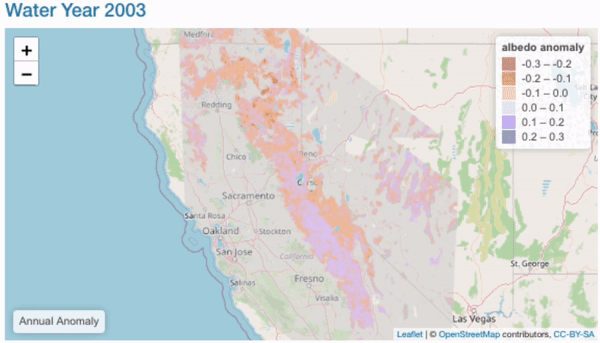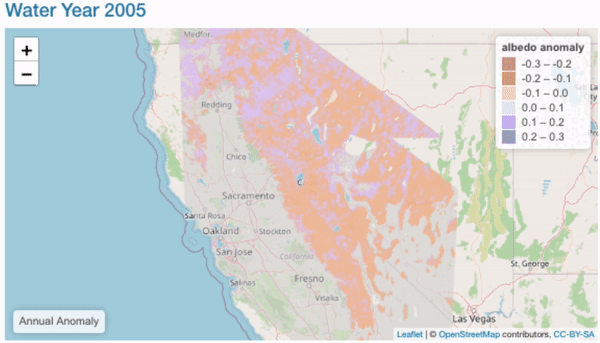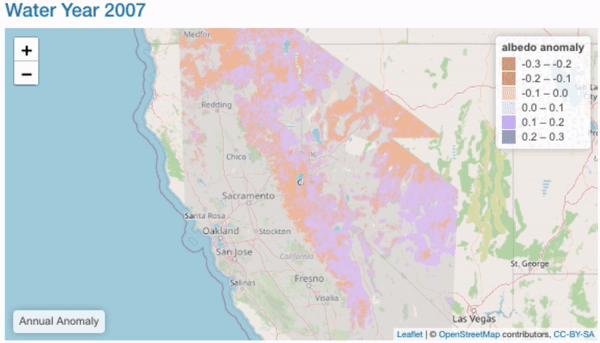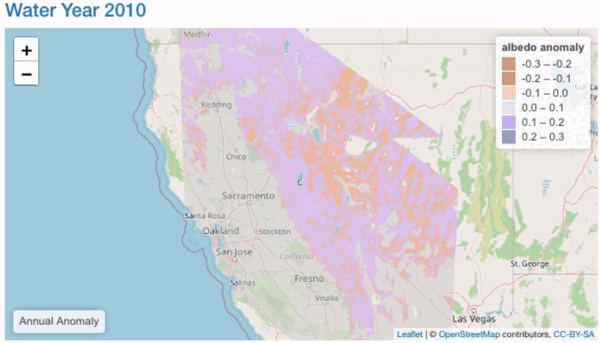
Objectives
Create an open source workflow for processing and visualizing snow data
Provide recommendations for the Snow Today website
Create interactive visualizations
3. Improve data usability through tutorials in Python
Tutorials
1. Download and Explore Datasets
2. Process and Format Data
3. Analyze and Visualize Snow Data
Contributions
Background
In February 2021 the Houston, TX metropolitan area experienced wide scale power outages due to electrical infrastructure failure during winter storms and extreme cold temperatures
1.4 million customers without power
Project overview
- Load satellite imagery
- Create blackout mask
- Identify residential buildings within blackout area
- Spatially join census data to blackout areas

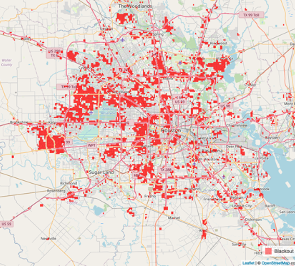
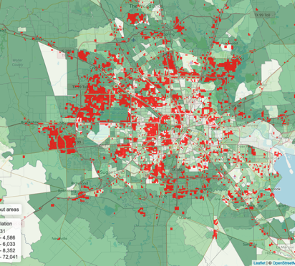
+144,000 households without power
Percent white
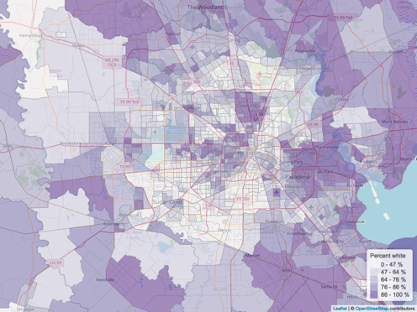
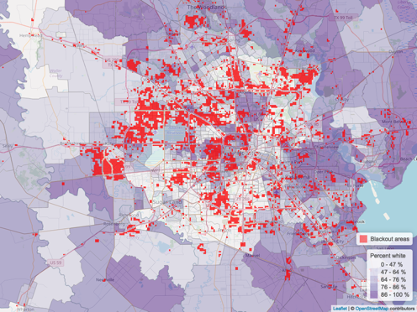
Percent bipoc
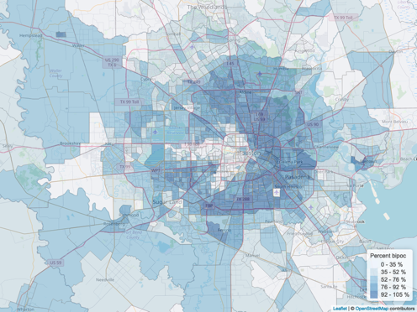
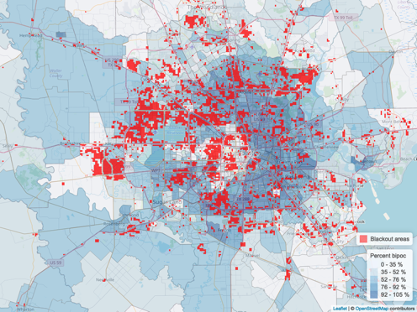
Statistical Analysis
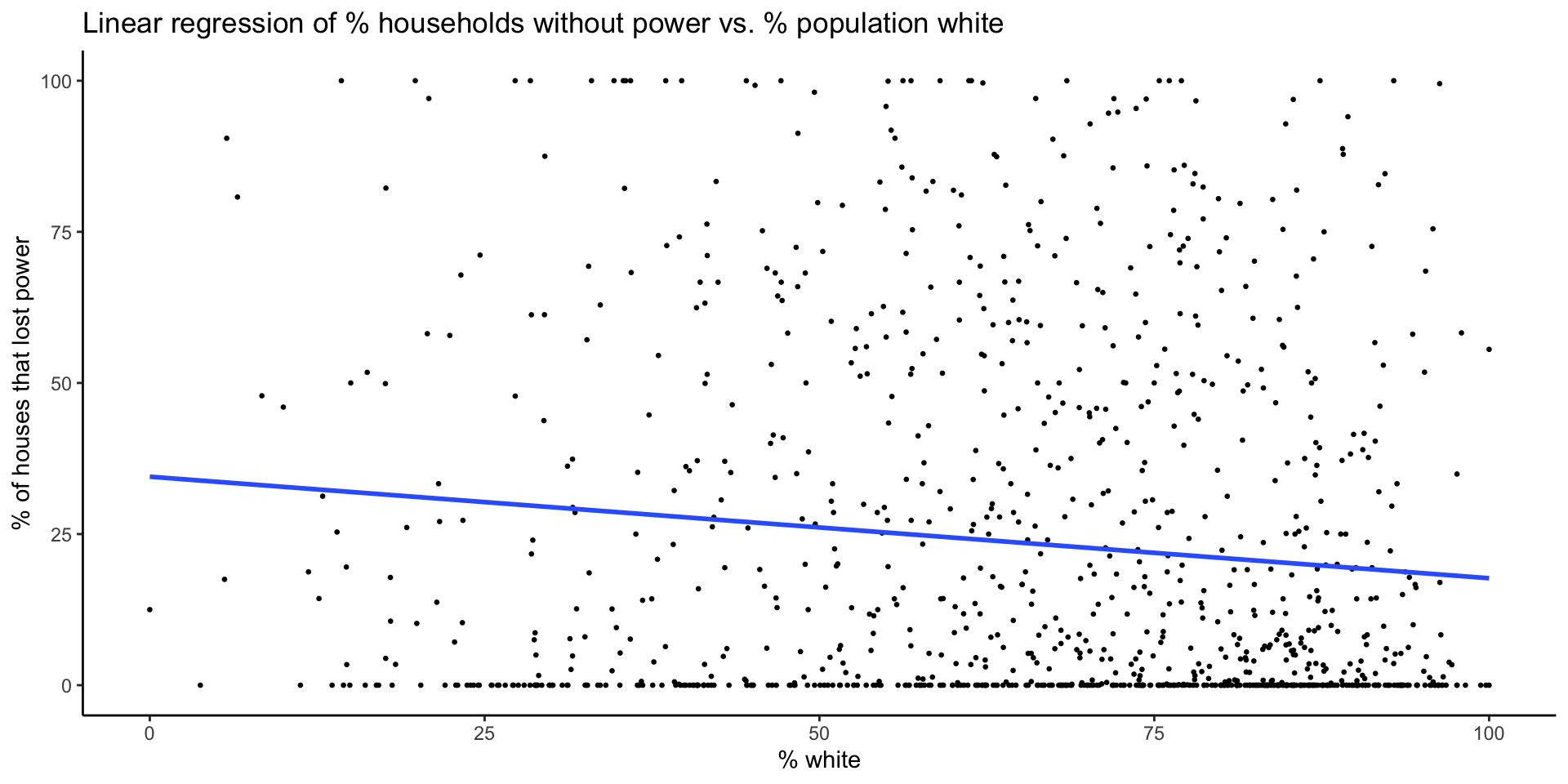
# linear regression model
model_pct_white <- lm(data = blackout_census_data, pct_houses_that_lost_power ~ pct_white)
#plot
plot_model_pct_white <- ggplot(data = blackout_census_data, aes(x = pct_white, y = pct_houses_that_lost_power)) +
geom_point(size = 0.5) +
geom_smooth(method = lm, formula = y~x, se = FALSE) +
theme_classic() +
labs(x = "% white", y = "% of houses that lost power",
title = "Linear regression of % households without power vs. % population white")
plot_model_pct_whiteStatistical Analysis
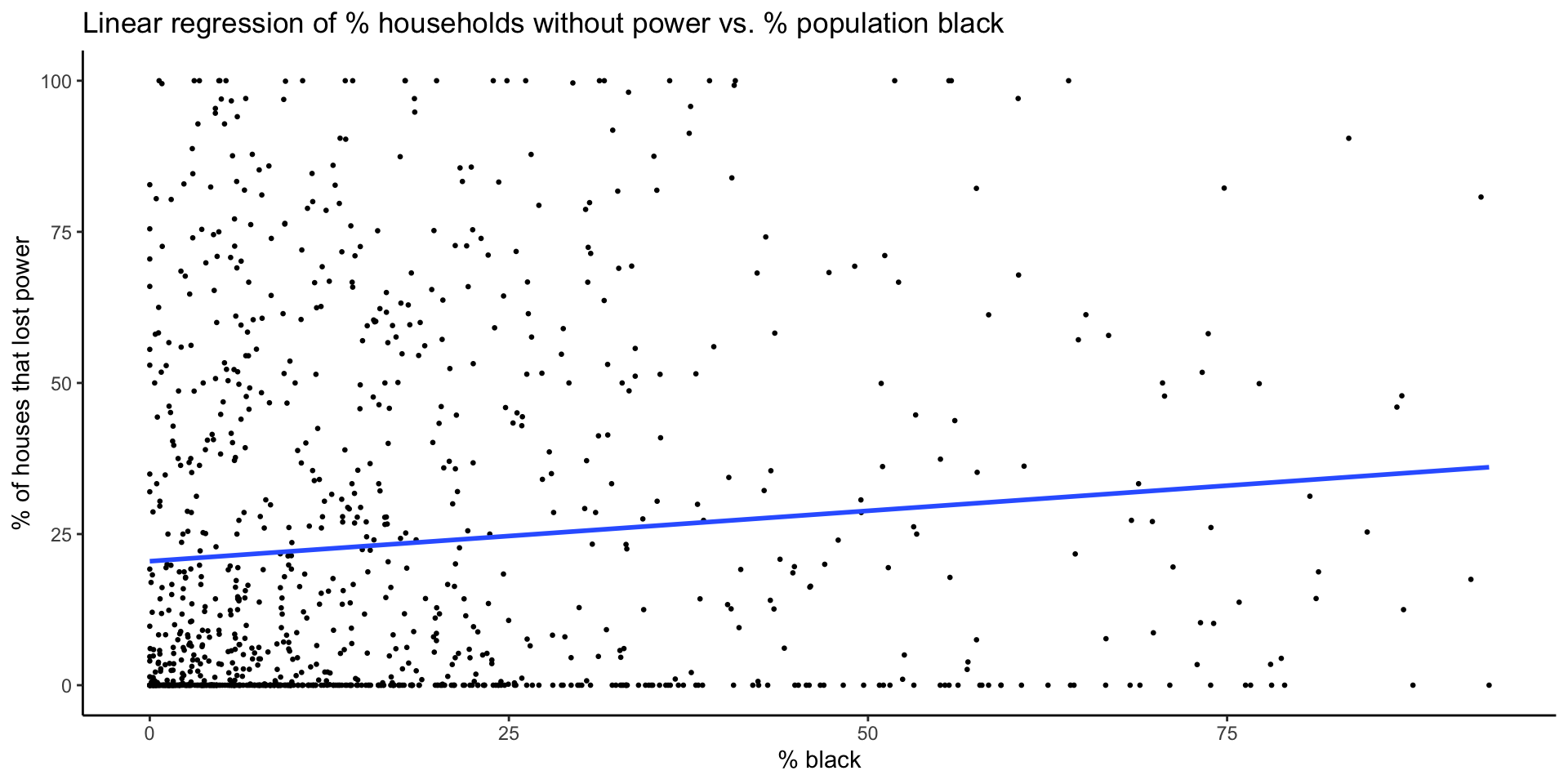
# linear regression model
model_pct_black <- lm(data = blackout_census_data, pct_houses_that_lost_power ~ pct_black)
# plot
plot_model_pct_black <- ggplot(data = blackout_census_data, aes(x = pct_black, y = pct_houses_that_lost_power)) +
geom_point(size = 0.5) +
geom_smooth(method = lm, formula = y~x, se = FALSE) +
theme_classic() +
labs(x = "% black", y = "% of houses that lost power",
title = "Linear regression of % households without power vs. % population black")
plot_model_pct_blackResults
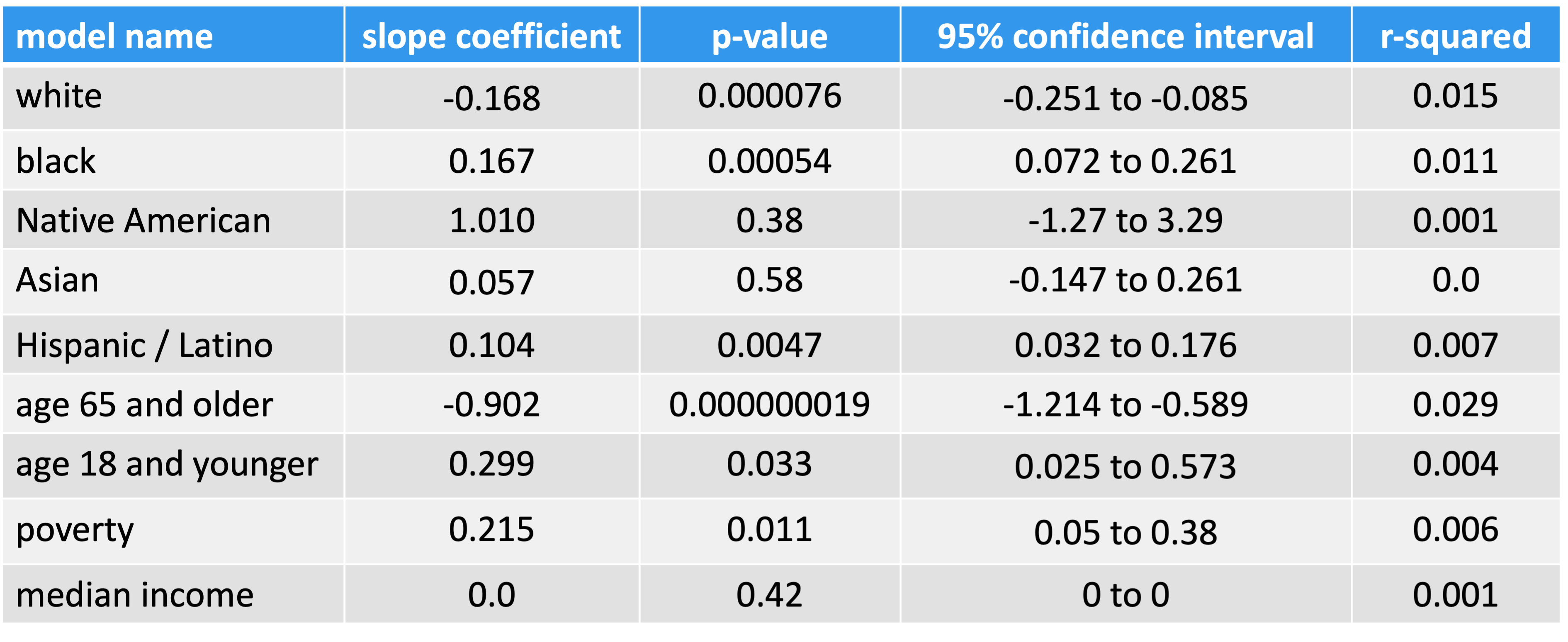
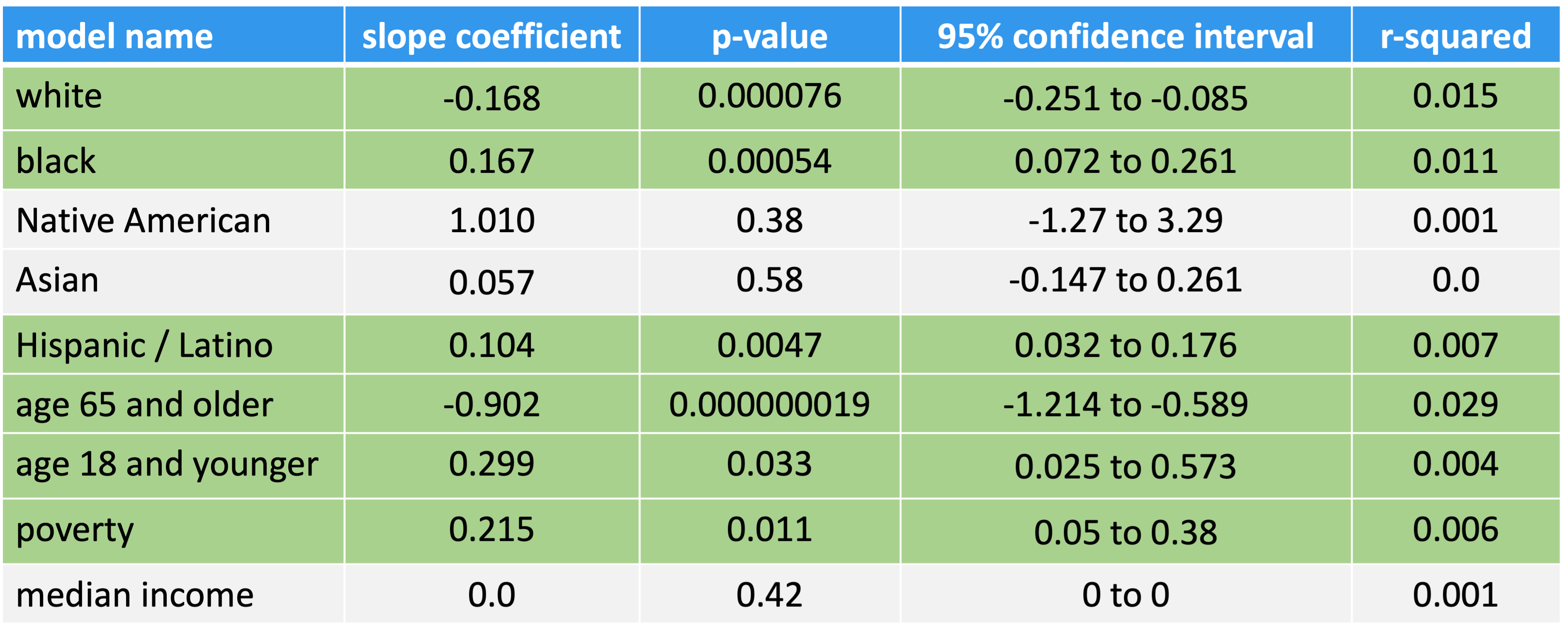
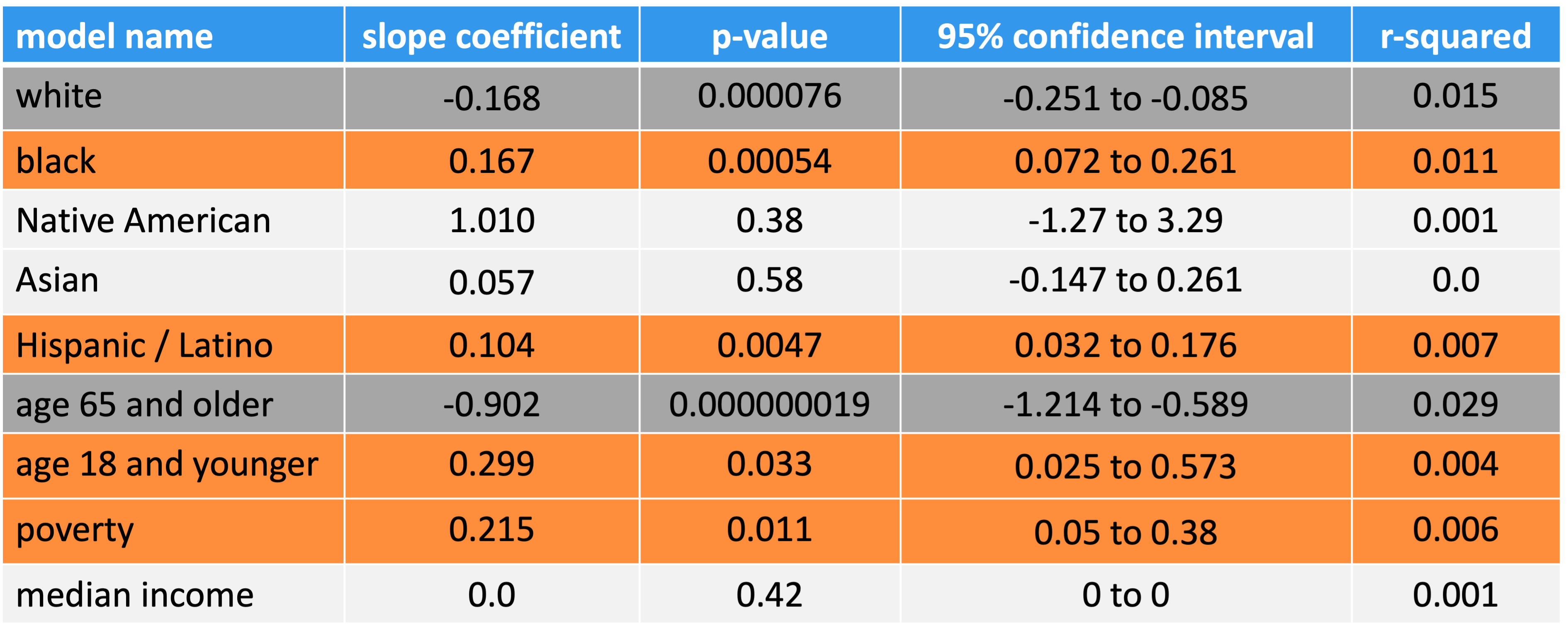
Conclusions
While race, age and income accounted for small portions of the overall variance in residential power outages, this analysis suggests some racial and economic inequality.
Electric utilities should evaluate infrastructure and asset management plans in areas with higher proportions of people of color and poverty
There is a need for more equitable responses to natural disasters
 image source1
image source1